

I Ran a Search Quality Evaluation on Zepto in One Afternoon. Here’s What I Found
What used to take a team of engineers, data scientists, and human judges over several days, two of us did in a few hours. Here’s how.

A few years ago, when I was leading search at Zepto, running a proper search quality evaluation meant a small project in itself. You needed engineering time to pull query logs, a pipeline to hit the search API at scale, a relevance judging tool, a panel of trained human judges working through hundreds of results, and someone to crunch the nDCG numbers at the end. The whole thing, from kickoff to results, would take several weeks.
Last week, I ran the same evaluation in one afternoon. Just me and Claude.
What is nDCG and Why Does It Matter?
nDCG (Normalized Discounted Cumulative Gain) is the standard way to measure search ranking quality. The intuition is simple: if a user searches for “milk” and the most relevant result appears at position 1, that’s better than if it appears at position 7. A result buried lower in the list is worth less, even if it’s the right one. nDCG captures this by giving higher credit to relevant results that appear earlier.
The score runs from 0 to 1.
In practice, nDCG gives you two things: a single headline number to track over time (is search getting better or worse?) and per-query scores that tell you exactly where things are breaking down. It’s the difference between “search quality improved” and “search quality improved for masala queries but degraded for brand navigational queries.”
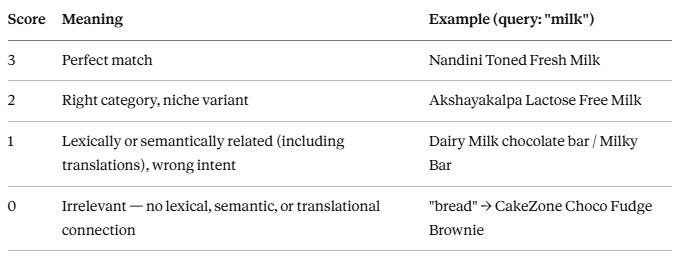
For this evaluation, I judged results on a 0–3 relevance scale:
The Challenges, and How I Solved Each One
1. No production query data
I don’t work at Zepto anymore. I don’t have access to their query logs. Real search quality evaluations start with actual user queries, ranked by frequency. I had none of that.
Solution: I asked Claude to generate a synthetic dataset of high-frequency queries for an Indian quick commerce platform. Claude generated a list of 5,000 queries in around 15–20 minutes, covering everything from staple English queries (”milk”, “eggs”, “atta”) to Hindi terms (”pyaaz”, “haldi”, “namak”) to Marathi (”kanda”), brand queries (”amul milk”, “parle g”, “maggi”), and specific masalas (”rasam powder”, “pav bhaji masala”).
For the POC, I focused on the top 100.
2. Getting search results at scale
How do you fetch the top 10 results for 100 queries without manually typing each one into an app?
My first instinct was Claude in Chrome, a browser automation tool that can interact with web pages. I rejected it. It’s in beta, it’s brittle, and for a serious evaluation you need reliable, structured data — not screen-scraped results that vary with rendering and session state.
Solution: Zepto has an official MCP (Model Context Protocol) server at mcp.zepto.co.in. Once connected, Claude could call Zepto’s search API directly: structured, reliable, no scraping, real catalog data. I fetched top 10 results for all 100 queries in batches, with the store set to central Bangalore coordinates.
One engineering lesson from this: silent failures in batched API calls are dangerous in evaluation pipelines. My first pass flagged 13 queries as “zero result”: shampoo, honey, oats, fish, and others. Shampoo returning zero results on Zepto? I pushed back, re-fetched each individually, and found 12 of the 13 had perfectly good results. The batch calls had silently dropped them. This would have pulled my headline nDCG from 0.947 down to 0.773. Always verify zero-result queries individually.
The one genuine zero-result query was paracetamol — a dark store inventory gap, not a platform failure. The same query from a different Bangalore location returns Dolo-500, Pacimol, Calpol at the top.
This is a broader limitation worth stating plainly: all 100 queries were fetched from a single dark store. Inventory varies across stores, and a zero-result query from one store may return 10 relevant results from another. My scores are accurate for the store I tested, not a verdict on Zepto’s search quality overall.
3. Building relevance judgment guidelines
Building relevance judgment guidelines typically takes hours. You have to work through what “good” and “bad” looks like across head queries, torso queries, and a sample of the tail, and the answers are rarely obvious.
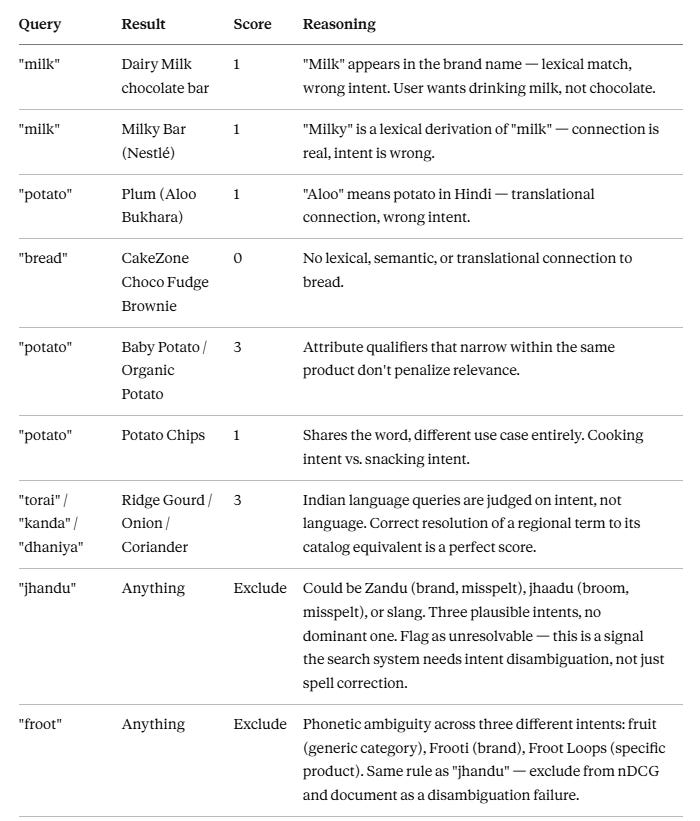
Solution: I brainstormed the guidelines collaboratively with Claude. I’d propose a case, Claude would give a score and reasoning, I’d push back or add a wrinkle, and the guideline would get refined. The whole process took about 30–40 minutes and produced 11 documented rules. Doing this alone, with no sparring partner, would have taken a couple of hours at minimum, and the output would have been less thorough.
A few of the cases that forced real judgment calls:
4. LLM-as-judge
At Zepto, this step would have meant working with an external relevance judging agency and waiting a couple of weeks for results back.
Solution: Claude judged all 990 rows (99 queries × 10 results — paracetamol returned zero results and contributed no rows), applying the 0–3 scale consistently against the documented rules.
One limitation of LLM-as-judge surfaced during review. Claude scored “Ginger Mango” at position 1 for the query “ginger” as a 0 — reasoning that it was a mango variety, not the spice. It is actually a cultivar of ginger with a mango-like aroma. The search engine was right; Claude was wrong. Without real-world product knowledge, an LLM will misclassify niche or unfamiliar products that look wrong on paper but are correct. Human review of low-scoring queries is essential before drawing conclusions from the scores.
What the Numbers Said
Headline: Mean nDCG@10 of 0.947 across 100 queries.
Zepto’s basic relevance is strong: 79.8% of all judged results scored a perfect 3.
Category breakdown:
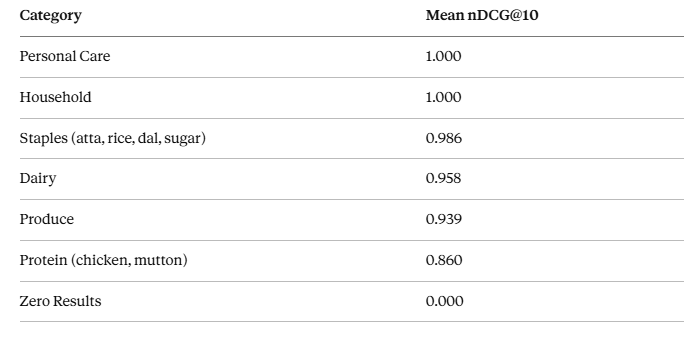
Why some scores are lower — and what’s actually causing it
After verifying the lower-scoring queries against the Zepto app, the picture is clearer than the raw numbers suggest. Almost every apparent relevance failure turned out to be one of three things, not an organic ranking problem:
Sponsored placements: mutton (0.728), coriander (0.706), amul milk (0.772), rasam powder, water bottle, coca cola, pepsi, sprite — all had irrelevant results at top positions confirmed as ads. The nDCG scores reflect the degraded user experience accurately; the root cause is the ads layer. A low nDCG on “mutton” is not a search team problem — it’s an ads insertion point. The right question is whether the conversion impact of those placements is worth the revenue.
MCP representation gap: “lemon” appeared to show basket-affinity bleed at positions 3–10 (Curry Leaves, Garlic, Mint). On the app, those positions are a “related products” section that appears after the genuine search results run out. Zepto has only 2 lemon SKUs. The MCP flattens this into a single ranked list with no section break, making deliberate product behavior look like a ranking failure.
One genuine organic issue: Plum (Aloo Bukhara) appearing at position 8 for “potato.” The word “aloo” means potato in Hindi, and it appears in the product name — a vocabulary collision that the ranking model didn’t catch. Scored as 1 (lexically related, wrong intent) rather than a hard failure.
I kept all nDCG scores as-is throughout. nDCG measures what a user actually sees, regardless of how a result got there. The scores are accurate as a measure of user experience. What the verification exercise adds is the diagnostic layer — understanding whether a low score should trigger a conversation with the search team, the ads team, or the MCP product team.
The MCP blind spot worth noting: the API returns results in ranked order with no metadata distinguishing organic results, sponsored placements, or related product sections. For anyone building a conversational ordering interface on top of Zepto MCP, this means users could be presented with sponsored products with no indication they are paid placements. That’s a product decision worth making consciously.
Takeaways
1. The framework is replicable. The entire evaluation ran on a synthetic query dataset and a public MCP integration. Any search PM at any Indian e-commerce company could replicate this for their own platform.
2. Guidelines matter more than the model. The quality of LLM-as-judge output is almost entirely determined by the quality of the guidelines you give it. Vague guidelines produce noisy judgments. Precise guidelines, with worked examples for edge cases, produce reliable ones. Budget serious time for guidelines design; it is the core intellectual work, not a prerequisite to get through quickly.
3. Indian q-commerce search evaluation needs India-specific guidelines. “Dhaniya” returned coriander powder before coriander leaves. “Tamatar” returned tomato chutney at position 1. “Daliya” returned foxtail millet at position 1. These are transliteration and intent resolution failures that no English-language search quality framework covers out of the box. Building evaluation guidelines for Indian platforms requires starting from Indian language examples.
4. Silent API failures will corrupt your evaluation. In batched API calls, dropped results don’t throw errors; they just disappear. My unchecked nDCG would have been 0.773; the corrected number was 0.947. That is a 17-point error from a silent failure, not a bad model. Always verify zero-result queries individually.
5. nDCG scores measure user experience, not ranking engine quality. Keeping the scores as-is for queries with known sponsored placements is the right call. What a user sees is what matters. The diagnostic layer (was this a ranking failure or an ads decision?) is separate from the measurement. A complete evaluation setup would report both an organic-only nDCG and a blended nDCG, using ad metadata the internal team would have but which the MCP does not currently expose.
6. The MCP ad slot gap matters for ordering interfaces. If you are building a conversational product ordering experience on top of Zepto MCP, the API gives you no signal about which results are sponsored. A user asking Claude to “find me mutton” could be presented with a sponsored masala brand at position 1 with no indication it is a paid placement. Whether that is acceptable is a product decision, but it should be a conscious one, not an accidental one.
Conclusion
I was able to do this working MVP within one afternoon.
A production version would add: real query logs with frequency weights, multi-judge consensus for disputed cases, ad slot metadata, multi-city coverage across different dark stores, and longitudinal tracking to measure quality changes over time. And some more Claude tokens. :)
Methodology notes: Results fetched via Zepto MCP from a single dark store serving central Bangalore (store ID b1403534), June 2026. Inventory varies by dark store; queries returning zero results from this store may return relevant results from other stores. nDCG scores reflect the experience of a user served by this specific store and should not be generalised to Zepto’s search quality platform-wide. A production evaluation would run across multiple stores weighted by query volume share.
The dataset, relevance guidelines, and judged CSV from this evaluation are available on request. If you are a search PM at an Indian e-commerce company and want to run this on your own platform, feel free to reach out.
Parth Kanungo is a Staff Product Manager specializing in search, recommendations, and consumer products. He has previously led search quality and relevance at Zepto, PharmEasy and Blibli.com